Handling uploaded objects to S3 with SQS and Lambda
Amazon S3 is used in almost every AWS-based application, and as such, it’s a very important part of any architecture.
1. Automated notifications
When dealing with S3, it’s often required to apply some logic when users or applications upload objects to the bucket.
Luckily, S3 has an event notification mechanism and it lets us configure different target services when something interesting happens in S3 (object creation or deletion, just to mention two). These targets can be SQS, SNS or Lambda.
2. Architecture
This architecture pattern has a standard SQS queue configured as the target when objects get uploaded to S3 (s3:ObjectCreated:*).
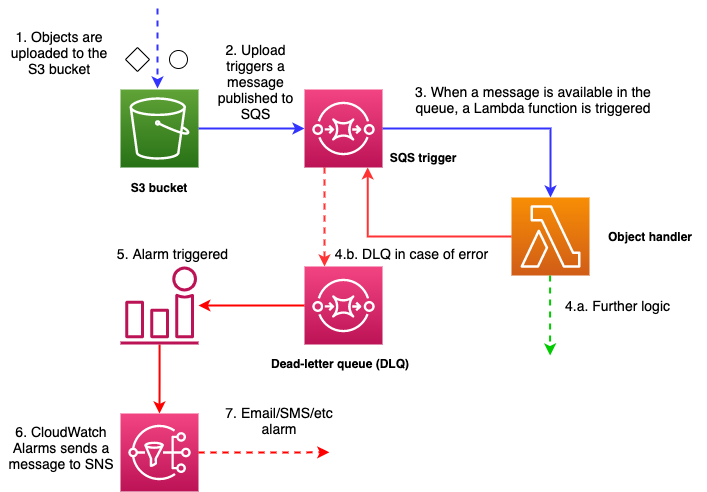
As soon as the queue receives a message from S3, it will trigger a Lambda function (creatively named as S3HandlerFn). The SQS event object looks like this:
{
"Records": [
{
"messageId": "059f36b4-87a3-44ab-83d2-661975830a7d",
"receiptHandle": "AQEBwJnKyrHigUMZj6rYigCgxlaS3SLy0a...",
"body": "Test message.",
"attributes": {
"ApproximateReceiveCount": "1",
"SentTimestamp": "1545082649183",
"SenderId": "AIDAIENQZJOLO23YVJ4VO",
"ApproximateFirstReceiveTimestamp": "1545082649185"
},
"messageAttributes": {},
"md5OfBody": "e4e68fb7bd0e697a0ae8f1bb342846b3",
"eventSource": "aws:sqs",
"eventSourceARN": "arn:aws:sqs:us-east-2:123456789012:my-queue",
"awsRegion": "us-east-2"
},
{
"messageId": "2e1424d4-f796-459a-8184-9c92662be6da",
"receiptHandle": "AQEBzWwaftRI0KuVm4tP+/7q1rGgNqicHq...",
"body": "Test message.",
"attributes": {
"ApproximateReceiveCount": "1",
"SentTimestamp": "1545082650636",
"SenderId": "AIDAIENQZJOLO23YVJ4VO",
"ApproximateFirstReceiveTimestamp": "1545082650649"
},
"messageAttributes": {},
"md5OfBody": "e4e68fb7bd0e697a0ae8f1bb342846b3",
"eventSource": "aws:sqs",
"eventSourceARN": "arn:aws:sqs:us-east-2:123456789012:my-queue",
"awsRegion": "us-east-2"
}
]
}
A few things to note here:
- SQS can batch multiple records (messages) in one notification, so the Lambda function needs to handle that.
- The
bodyproperty contains the message itself. TheattributesandmessageAttributesare also useful properties where we can send meta data to the Lambda function.
In our example, S3 will send a message to the dedicated SQS queue after an object gets uploaded to the bucket. The body property (whose value is a stringified object) of each Record has the reference to S3 (after parsing):
"Records": [
{
// ...
"eventName": "ObjectCreated:Put",
"s3": {
// ...
"bucket": {
"name": "THE NAME OF THE BUCKET",
// ...
},
"object": {
"key": "THE KEY OF THE UPLOADED OBJECT",
// ...
}
}
}
]
We can see that Lambda doesn’t receive the object itself but just a reference to the bucket and the object.
It means that the function needs to extract the bucket name and object key from the record and explicitly download the object from S3 using the GetObject API call. The Bucket and Key parameters for the API call will be the bucket name and object key, respectively. They will then get passed on to Lambda in the SQS message.
From here, the Lambda function can do whatever it needs to do with the object (transforming, uploading to another bucket, persist to a database, etc.).
3. Advantages and disadvantages
This pattern has the following advantages and disadvantages.
3.1. Advantages
Decoupling
When Lambda can’t keep up with the uploads for any reason (due to under-configured Lambda concurrency or downstream error, for example), the messages will remain in the queue so that they can be processed later. The retention period is four days by default, but it is configurable. I have set this value to 1209600 seconds in the template, which is 14 days (this is the maximum configurable value).
This way, no messages will be lost.
Automation
The process is fully automated, and there’s no need for manual intervention (as long as everything goes well, see below).
After Lambda has processed the message, it will delete it from the queue. It is good news for us because we don’t have to write code for this step in the function.
Re-try and dead-letter queue
If something goes wrong, i.e., if the Lambda function throws an error, the message will get back to the queue, and Lambda will try to process it again.
The RedrivePolicy of the queue determines how many times we want Lambda to try to process the message. If maxReceiveCount property is set to 2 (just like in the template in this case), Lambda can try processing the message three times before it is moved to the dead-letter queue, which is specified in the same section of the CloudFormation template.
Alarm on the dead-letter queue
A CloudWatch alarm can be set up if the number of messages exceeds a pre-defined threshold in the dead-letter queue.
If messages appear in the dead-letter queue, it will indicate that something went wrong in the source queue.
When such an event occurs, CloudWatch alarm will publish an event to an SNS topic, and we can decide how we want to receive the notification (email, SNS, Slack, etc.). Upon receiving the alert, we can investigate what has happened with the messages.
3.2. Disadvantages
Re-drive
Re-trying the messages has some disadvantages as well. When many objects get created in the bucket in a short period, the source queue can build up very quickly if any error occurs in the Lambda. If, for example, there is a formatting error and the function tries to read a property from the uploaded object that doesn’t exist, it will throw an error. Even if SQS resends the message to Lambda in this case, the result won’t (and can’t) be different, and the error will come up again.
A sophisticated error handling practice can decide which errors are worth re-trying (usually system and throttling errors) and which ones are not (for example, validation or formatting errors).
Slow processing time
The processing time of the accumulated messages can be slow. Depending on the number of messages, it can take any time from a few seconds to a few hours.
In general, if everything goes well, this pattern works very quickly, usually within a second, but in case of a high volume when the consumer (the Lambda function) can’t cope with the load, the service can slow down.
We can reduce the likelihood of slow queue processing time with the proper configuration of the function (timeout, error handling, concurrency).
At least once delivery
Standard queues have at least once delivery, which means that one message can appear more than once. Therefore, the Lambda function needs to be idempotent and shouldn’t treat the same message differently.
4. Summary
This pattern is an often-used way to handle S3 events and works well in most circumstances.
The code and the CloudFormation template can be downloaded from the GitHub repo of the project.
Thanks for reading and see you next time.