Building MongoDB-based event-driven applications with DocumentDB
Table of contents
- 1. MongoDB vs DynamoDB
- 2. The scenario
- 3. MongoDB change streams
- 4. Architecture
- 4.1. Overview
- 4.2. Detailed view
- 5. Considerations
- 5.1. Not production-ready
- 5.2. Testing the app
- 5.3. Connecting to the database cluster
- 5.4. Direct integration
- 5.5. Other event-driven options
- 6. Summary
- 7. Further reading
1. MongoDB vs DynamoDB
I like DynamoDB and use it where it makes sense. I like the fast speed, the elasticity and the fact that it often has a negligible cost compared to other database options.
But sometimes we have to consider other NoSQL options, like MongoDB. Why do we want to choose MongoDB over DynamoDB? Here are some reasons:
- The application needs to store items as JSON documents.
- Documents are deeply nested, and it would be a lot of effort to transform them into simple attributes that DynamoDB expects.
- MongoDB has a simple JavaScript syntax. DynamoDB has a steeper learning curve.
- Your team lead or line manager is afraid of anything new, and they want you to use the good old MongoDB.
There might be other reasons (feel free to write them in a comment), but these ones come to mind now.
2. The scenario
So, MongoDB is the chosen database. Do we have to abandon the event-driven patterns we can implement with DynamoDB Streams?
The good news is no, we don’t.
MongoDB supports change streams, which applications can use to react to real-time data changes.
Luckily, AWS has a MongoDB-compatible NoSQL database called DocumentDB, and the latest engine version (5.0.0) now supports change streams.
3. MongoDB change streams
Change streams store event objects for 3 hours by default, but we can extend the duration up to 7 days. We must explicitly enable change streams on a database or specific collections in the database.
A good spot for the change stream code is where we write (and probably cache) the MongoDB client code:
// Create the connection and get the client
const client = await connectToDatabase();
// Enable change streams on the collection
const adminDb = client.db('admin');
await adminDb.command({
modifyChangeStreams: 1,
database: DB_NAME,
collection: COLLECTION_NAME,
enable: true
});
Part of the connectToDatabase() function may be similar to this:
const secretsManager = new SecretsManagerClient();
export async function connectToDatabase(): Promise<MongoClient> {
// Get credentials from Secrets Manager
const secretCommandInput: GetSecretValueCommandInput = {
SecretId: process.env.DOCDB_SECRET_ARN,
};
const secretData = await secretsManager.send(
new GetSecretValueCommand(secretCommandInput)
);
if (!secretData.SecretString) {
throw new Error('Missing database credentials in config');
}
const secret = JSON.parse(secretData.SecretString);
const encodedUsername = encodeURIComponent(secret.username);
const encodedPassword = encodeURIComponent(secret.password);
const port = DOCDB_PORT || '27017';
const database = DOCDB_DATABASE || 'products';
const uri = `mongodb://${encodedUsername}:${encodedPassword}
@${DOCDB_ENDPOINT}:${port}/${database}?tls=true&replicaSet=rs0
&readPreference=secondaryPreferred&retryWrites=false`;
const client = new MongoClient(uri, {
tlsCAFile: <PATH_TO_ROOT_CERTIFICATE_PEM_FILE>,
tls: true,
});
await client.connect();
cachedClient = client;
return client;
}
As you can see, it’s a standard MongoDB connection function.
I want to highlight one thing in the code. DocumentDB integrates with Secrets Manager, where database secrets (username and password) are stored. The function must fetch these credentials before it can create the connection URI.
Now that we have enabled the change streams, let’s look at the architecture. How can we use the change stream feature in our applications?
4. Architecture
This article will present the simple design of an application where admin users can add products, and users can search for them.
4.1. Overview
The connection point to the application is an API Gateway, which has two endpoints: POST /product and GET /search.
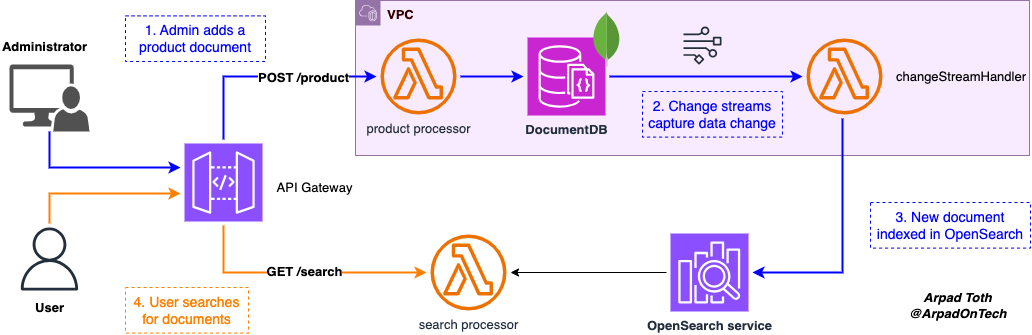
Administrators upload the new product info by sending the product object in the request body to the /product endpoint. In this sample project, part of the product schema looks like this:
{
"productId": 1001,
"productName": "Wireless Headphones",
"description": "Noise-cancelling wireless headphones",
"brand": "SoundPro",
"category": "Electronics",
"price": 199.99,
"currency": "USD",
"ratings": {
"averageRating": 4.7
},
// other product-related properties, many of which are nested
}
A Lambda function will act as the endpoint integration and save new products to the database.
As discussed above, I chose DocumentDB for the project because of the many nested properties in the document, and I want to store the document as is. I didn’t bother making the database and collection names very complex, and named both products.
A second Lambda function called changeStreamHandler watches the MongoDB change stream and indexes the new product documents in OpenSearch Serverless service. The function iterates over the events records and adds them to OpenSearch.
Finally, users can invoke the /search endpoint with a search expression to fetch matching product details. The search function in my little POC performs a multi_match query:
// ...other function code
// Search in OpenSearch
const response = await opensearchClient.search({
index: 'products',
body: {
query: {
multi_match: {
query, // User's search expression
fields: [
'productName^3',
'description^2',
'brand',
'category',
'ratings.averageRating',
],
},
},
sort: [{ _score: { order: 'desc' } }],
},
});
As the code above shows, the search expression looks for matching data in five fields.
Requests to OpenSearch must be signed with AWS Signature V4. The OpenSearch project npm package contains the AwsSigv4Signer method, which makes the signature simple:
import { Client } from '@opensearch-project/opensearch';
import { AwsSigv4Signer } from '@opensearch-project/opensearch/aws';
// ...
const client = new Client({
node: endpoint,
...AwsSigv4Signer({
region: 'eu-central-1',
service: 'aoss', // Amazon OpenSearch Serverless
}),
});
Let’s take a closer look at some key elements.
4.2. Detailed view
Functions in the VPC. It’s a shame, but as of today, DocumentDB is only available in a cluster format that runs managed instances. The cluster must be provisioned in at least two - preferably private - subnets in a VPC. There’s currently no serverless version available!
The product and changeStreamHandler Lambda functions interact with the database. As such, we must provision them, possibly in the same VPC private subnets. (Let’s not go into other VPC design options here.)
Security groups. The functions’ security groups must allow outbound rules to the security group assigned to the DocumentDB cluster. The DocumentDB security group must allow inbound traffic on port 27017 (the MongoDB default port) from the Lambda functions’ security group.
Event source mapping. Since the changeStreamHandler reads events from the change stream, Lambda will use the polling invocation model. We must configure an event source mapping, where, besides the usual stream settings, like batchSize or startingPosition, we must set the authentication option and specify the database and collection names the function will read events from. A sample CDK code with a low-level construct may look like this:
const eventSourceMapping = new cdk.CfnResource(
this,
'ChangeStreamEventSourceMapping',
{
type: 'AWS::Lambda::EventSourceMapping',
properties: {
FunctionName: changeStreamLambda.functionArn,
EventSourceArn: docdbClusterArn,
StartingPosition: 'LATEST',
BatchSize: 10,
Enabled: true,
SourceAccessConfigurations: [
{
Type: 'BASIC_AUTH',
// The ARN of the Secrets Manager secret
// that holds the connection info
URI: docdbSecret.secretArn,
},
],
DocumentDBEventSourceConfig: {
DatabaseName: 'products',
CollectionName: 'products',
},
},
}
);
We must also specify the Secret Manager secret’s ARN containing the DocumentDB cluster connection information (username and password).
NAT Gateway. For the functions to interact with DocumentDB via the event source mapping, we need to provision either a NAT Gateway or some VPC interface endpoints. The documentation will describe what endpoints are required in more detail. For the sake of simplicity, I created a NAT Gateway, but it might not be the best option for some industries where companies need to comply with strict regulations.
OpenSearch Serverless. Great option for proofs-of-concept (like this one) or teams that don’t want to manage OpenSearch clusters. It’s a fully managed service where we don’t have to worry about VPCs, security groups and NAT Gateways. The search function connects to OpenSearch Serverless through an https endpoint.
Permissions. Lambda functions provisioned in a VPC must have specific permissions other than those they use to connect to DocumentDB. The Lambda service needs to create ENIs - Elastic Network Interfaces, virtual network cards in the VPC -, so we must add the required permissions to the function’s execution role.
The product function also needs Secrets Manager (secretsmanager:GetSecretValue and secretsmanager:DescribeSecret) and KMS (kms:Decrypt) permissions since it needs to authenticate to DocumentDB.
5. Considerations
The result is a simple event-driven application, where we use streams to react to MongoDB data changes.
I want to highlight a couple of things, though.
5.1. Not production-ready
As it might be clear from the discussion above, this article does not cover the entire application.
The application is only a POC and is not production-ready. It only contains some core infrastructure elements.
Error handling, retries and monitoring should also be implemented in production workloads.
5.2. Testing the app
Besides the basic let’s call the endpoint and see what happens
method, I tested the application with a script, which made a batch of 5 parallel requests per second to the POST /product endpoint until 500 documents got uploaded to the database.
The architecture elements scaled well when needed, and I didn’t experience any bottlenecks.
5.3. Connecting to the database cluster
If you are like me and prefer connecting to databases from the terminal vs using a GUI, you are probably familiar with the MongoDB Shell.
But how can we connect to the DocumentDB cluster, which is provisioned in a private network, from outside?
We have a couple of options. One of them is to launch an EC2 instance in the same VPC, install mongosh on the instance, and copy the cluster connection command from the DocumentDB page in the console.
For example, we can then check which databases and collections have the change streams setting enabled:
db.runCommand({
aggregate: 1,
pipeline: [{$listChangeStreams: 1}],
cursor: {}
})
The response will look like this:
{
waitedMS: Long('0'),
cursor: {
firstBatch: [ { database: 'DB_NAME', collection: 'COLLECTION_NAME' } ],
id: Long('0'),
ns: 'test.$cmd'
},
operationTime: Timestamp({ t: 1747661570, i: 1 }),
ok: 1
}
Alternatively, you can use the usual GUI solutions like Studio 3T. Instructions on connecting to DocumentDB can be found in the official documentation.
5.4. Direct integration
I discussed one possible solution to connect OpenSearch and DocumentDB.
OpenSearch Ingestion pipelines support DocumentDB as source and keep the database in sync with OpenSearch without using an intermediary compute resource, like the changeStreamHandler function in this example. Ingestion pipelines support filtering, data transformation and enrichment, replacing the Lambda function with a managed feature.
The need to control the business logic and cost considerations (ingestion pipelines vs running a Lambda function) can help make the right architecture decision.
5.5. Other event-driven options
Indexing documents in OpenSearch is not the only action we can perform by building on change streams.
We can create fanout patterns by having the Lambda function publish a message to an SNS topic or an EventBridge event bus, allowing other (micro)services to react to the MongoDB state changes.
6. Summary
MongoDB change streams offer the option to implement event-driven patterns that react to document changes in the database.
DocumentDB is a NoSQL database with MongoDB compatibility, where version 5.0.0 supports change streams.
One implementation pattern is to index the newly created document in OpenSearch and provide users with a search box to perform advanced searches.
7. Further reading
Amazon OpenSearch Service Pricing - Ingestion pipelines pricing included
Create your first Lambda function - If you need help in creating Lambda functions
Creating an Amazon DocumentDB cluster - I can’t add more to the title