Creating Application Load Balancer rules for fast feature stack deployments
1. The problem
One day her boss gave Alice an exciting task.
She had to design a solution for QA analysts to test new developments in a key service. The solution must meet the following criteria:
- Testing must occur in the cloud to simulate the production environment as much as possible.
- The new feature may not block the CI/CD pipeline. It is because QA analysts don't have to test all new features. In addition, hotfixes should be out in production as soon as possible, so waiting for the tests to be complete can be suboptimal.
- The solution should be cost-optimized and use an existing environment's resources and database as much as possible.
- Developers should be able to build and tear down the feature environment quickly and without manual intervention.
Let’s see how Alice solved this challenge!
2. Existing architecture
The service in question uses ECS Fargate behind a private Application Load Balancer (ALB). The engineering team placed an HTTP API Gateway before the ALB that performs the authentication.
The simplified existing architecture looks like this:
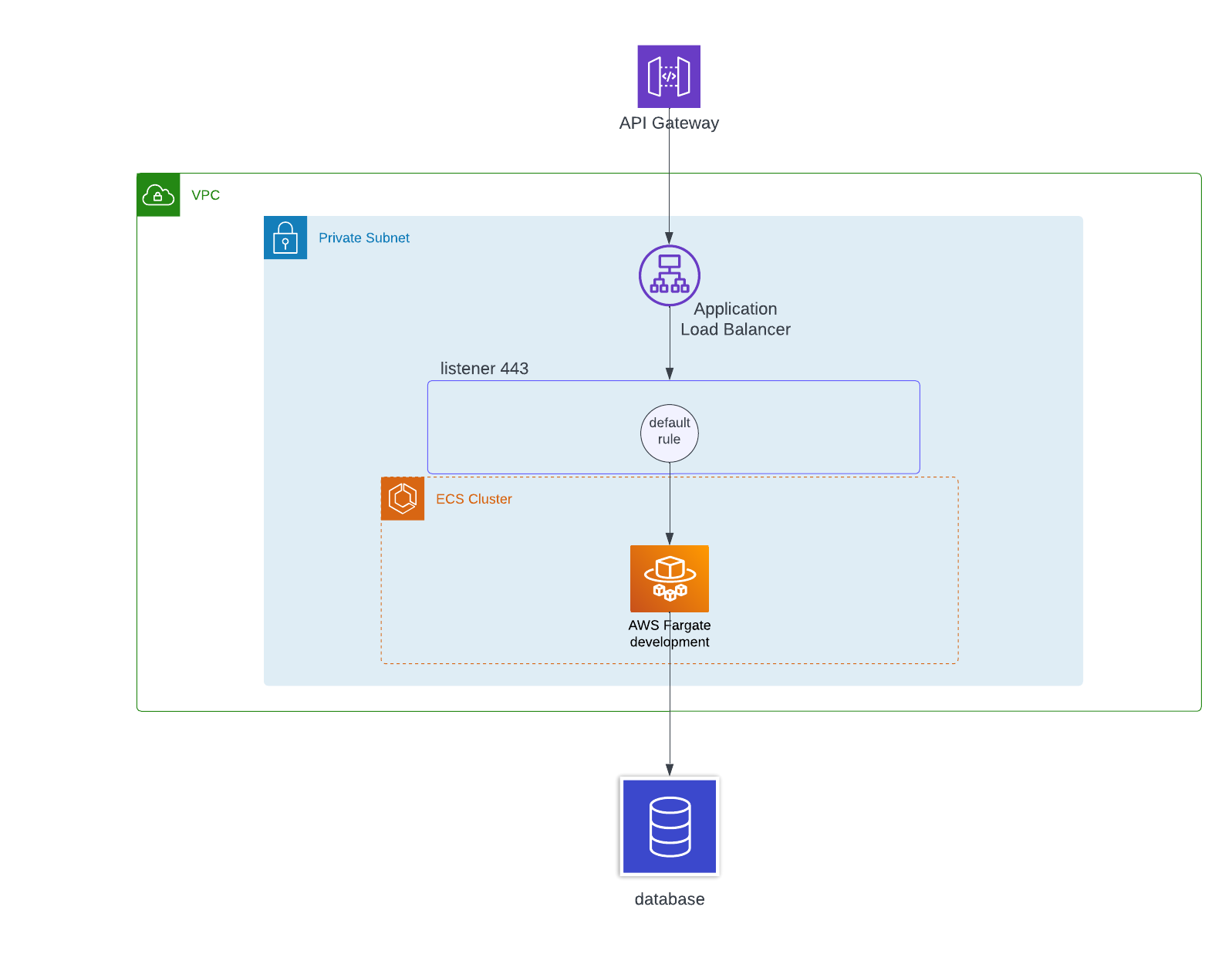
The ALB connects to the API Gateway via private integration. It means that the single point of contact to the service is the API Gateway, and everything else (load balancer, containers) is in private subnets isolated from the public internet.
The ALB has one listener on port 443, which currently has the default rule only. This rule forwards the request to the target group that contains the ECS service and containers.
The service runs on multiple deployments: development, staging, and production. Each environment has its database. The type of database can be anything since it doesn’t influence the solution described in this blog.
3. A solution
We can use the fact that the ALB is an application-level (Layer 7 of the OSI model) resource. It supports HTTP/S protocols and understands headers, paths, cookies, and other parts of an HTTP request.
Let’s see what we need to implement this solution.
For the sake of simplicity, the chart only contains one subnet in a single availability zone, which is OK for a non-production environment. We should always design production environments for high availability or even fault tolerance. It means that the resources should exist in multiple availability zones.
3.1. Unique URL for each ALB listener rule
We can have many different developments and GitHub pull requests at the same time, so we have to differentiate between them. If we could somehow create a different URL for each feature we want to test, we would be able to generate a fully-functioning non-blocking environment for the QA analysts.
We can achieve it by adding the pull request numbers to the URLs. PR numbers are unique, so we should be able to handle multiple PRs simultaneously.
After we have the unique request URL, the solution will use the ALB’s path-based routing feature. Each unique URL will have its own listener rule in the ALB that forwards the requests to the corresponding target group for the new feature.
The PR number will appear in two places. First, it will be the priority of the new rule we create for the feature.
Second, the rule will contain a condition. If the HTTP path pattern is */feature/PR_NUMBER_HERE/*, forward the request to the new target group. We generate one such rule for each feature (PR) we want to test.
ALB will apply the rule with the corresponding priority and condition when the path contains a specific PR number. If we don’t have any feature PRs or we call an endpoint with an invalid PR number, the flow will trigger the default rule. In this case, the request will go to the default environment, for example, development.
3.2. A new target group for each feature
It means that we have to create a new target group with targets for each feature we want to test. Technically it only requires a new service and containers, which function as the targets for the new rule.
3.3. Dedicated CloudFormation template
It’s worth creating a new CloudFormation or CDK template for the feature resources. Whenever we create a new PR on GitHub, we’ll provision a new CloudFormation stack that contains the containers with the new code. We can easily update the stack if we need to, for example, when we address comments on our PR.
3.4. Use the existing resources
Each feature deployment uses existing resources in the development environment. These resources are the database, API Gateway, ALB, listener, and VPC link.
Each feature branch will deploy and update quickly because the heavy services like ALB or ENIs that take time to provision already exist. The new resources are all serverless, and we only pay for what we use. It means that if the QA analysts are busy with other tasks and don’t touch the feature for some time, it won’t cost us anything.
Because we use existing resources, we should ensure that the development (or staging) stack exports the relevant ARNs or IDs. These resources are the ALB listener (so we can add the new rule), the VPC, and the subnets.
3.5. Use GitHub Actions
One more important part has left. How can we automate the deployment of the new resources?
We can use GitHub Actions. When someone creates a PR, they can add a specific label to the PR. This label will trigger the deployment of the feature stack.
The CDK code will have the PR number as an environment variable and add this unique identifier to the stack’s name. For example, if the pull request number is 123, the automation will deploy the stack named my-service-123-stack.
After the QA people have tested the new feature, we can merge the PR or remove the label. Both actions will trigger the deletion of the feature stack.
3.6. Put it together
The final solution will look like this:

4. Alice is happy
Alice’s team now has a fast, non-blocking solution for testing new features in the cloud.
They are good until the number of PRs reaches 50000 (the highest rule priority we can set). It should be more than enough because chances are that the service won’t operate in its current form by the time they create 50000 pull requests.
They can also have a maximum of 100 concurrent PRs (the limit for the number of rules per ALB). It’s also sufficient for Alice and her team since they usually have no more than 6-7 feature PRs simultaneously.
Alice’s solution works not only with Docker containers but any services that we can attach to an ALB as a target in a CloudFormation stack. For example, we can use Lambda functions, Kubernetes pods, or EC2 instances.
5. Summary
We can use the path-based routing feature of the Application Load Balancer to create non-blocking, fully functional stacks in AWS when we want to test our new features. The solution is automated and easy to deploy and tear down.
We also save costs by using existing resources and deploying only serverless components meaning we only pay for what we use.
6. Further reading
Quotas for your Application Load Balancers - Service limits for ALBs
Amazon ECS on AWS Fargate - ECS orchestration with Fargate hosting